Let’s be honest about graph databases. For a long time, there was a running joke (or at least a collective anxiety) among DBAs and DevOps engineers: “Graphs are amazing for small, highly connected datasets, but the moment you hit massive scale, good luck.”
We’ve all heard the warnings. You build a beautiful graph model on your laptop, everything runs flawlessly in Docker, and then the data science or fraud team tells you they need to scale it to tens or hundreds of terabytes. Suddenly, you’re sweating over RAM limitations, vertical scaling costs, and the absolute nightmare of trying to shard a graph without breaking your traversals.
Well, you can officially put that anxiety to rest. Neo4j has introduced Infinigraph, a brand-new distributed architecture integrated into the Graph Intelligence Platform.
The headline? Neo4j does scale. Seamlessly. Horizontally. Into the hundreds of terabytes.
Here is exactly what this means for your architecture, your deployment pipelines, and your sanity.
The Elephant in the Server Room: Why Graph Scaling Used to Hurt
Traditional database sharding is relatively straightforward: you split your users by ID or your logs by date, and you push them onto separate machines.
But a graph is defined by its connections. If you blindly slice a graph across multiple servers, a single multi-hop query (like looking for a fraud ring or tracing a supply chain) forces your database to constantly hop across network boundaries. Your query performance plummets, your network saturates, and your DevOps team starts updating their resumes.
Because of this, engineering teams often resorted to complex workarounds: separating operational (OLTP) and analytical (OLAP) workloads, building massive ETL pipelines, and duplicating storage.
Enter Infinigraph: Real Distributed Architecture
Infinigraph changes the game by introducing a true distributed graph architecture that scales to 100TB+ workloads. It handles the scaling bottleneck through a clever engineering approach called property sharding. Instead of ripping the core topology of your graph apart, Infinigraph distributes the massive property sets, wide metadata documents, and heavy vector embeddings across a cluster while keeping the core graph structure logically whole.
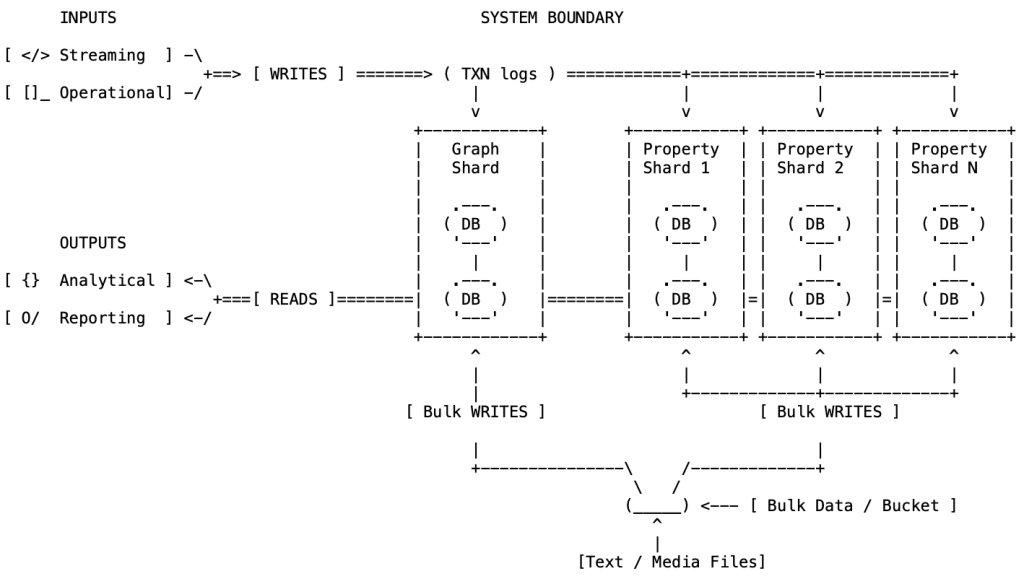
Here is how it actually works under the hood inside a Neo4j Autonomous Cluster:
- The Graph Shard (The Core Topology): One specialized shard stores the absolute essentials—nodes, relationships, labels, and unique identifiers. Because it isn’t bogged down by heavy text or vectors, this shard stays lean and fits into memory for lightning-fast traversals.
- The Property Shards (The Massive Distribution): Properties are separated, hashed, and distributed evenly across a cluster of specialized property shards.
- Full High Availability & Fault Tolerance: The graph shard forms a core Raft group that manages transactions, availability, and failover. Data is then propagated to the property shards via transaction logs. Need more read throughput or redundancy? You can use more shard or scale the graph shards by adding secondaries and the property shards by adding replicas.
From Laptop to Multi-Node Cluster (Without Changing Code)
The absolute best part of this architecture for developers and DevOps is deployment predictability. The database commands map directly from your local dev sandbox to enterprise production clusters.
On your laptop, you can play around with standard single databases. If you want to simulate a sharded layout locally for testing, you can use Neo4j’s composite database tooling. But when you move to production, you unleash the full power of Infinigraph using native CREATE DATABASE cluster syntax.
Let’s look at how the deployment configuration evolves from a traditional cluster setup to a property-sharded Infinigraph setup:
Traditional Cluster Database (Non-Sharded)
// Creates a standard database mirrored across 3 core cluster nodes
CREATE DATABASE foo
TOPOLOGY 3 PRIMARIES;
Infinigraph Distributed Database (Property-Sharded)
// Creates a graph topology shard backed by 4 property shards,
// each configured with 2 replicas for high availability
CREATE DATABASE foo
SET GRAPH SHARD { TOPOLOGY 3 PRIMARIES }
SET PROPERTY SHARDS { COUNT 4 TOPOLOGY 2 REPLICAS };
From the application’s perspective, nothing changes. Your drivers connect to the cluster exactly the same way. Your developers write the exact same Cypher queries. The graph engine automatically handles routing data to the correct shards behind the scenes.
Real-World Use Cases: Where This Saves the Day
To see why this is a game-changer, let’s look at two massive architectural patterns that used to break traditional graph setups.
1. GenAI & GraphRAG at Scale (The Social Network / Identity Layer)
Imagine building a global network application: think massive social graphs or enterprise identity layers mimicking an LDBC/SNB benchmark dataset. You have hundreds of millions of users, deep behavioral connections, and a massive footprint of full-text metadata. To make things more intense, you add GenAI capabilities, hanging heavy vector embeddings (like a 1536-dimensional array) off every single node for semantic graph searches.
- Without Infinigraph: the vector indexes and property bloat choke your page cache. Your cluster nodes stall because they are trying to load gigabytes of vector data into RAM alongside the graph layout.
- With Infinigraph: your graph shard processes structural queries and multi-hop traversals instantly. The massive vector arrays, text payloads, and bio documents live comfortably across your property shards.
2. High-Throughput Real-Time Fraud Engines
Picture a financial transaction graph where thousands of credit card transactions stream into the system every second. Every transaction node carries deep JSON metadata payloads, merchant locations, risk scores, and device fingerprints.
- Without Infinigraph: High-concurrency writes stall because the single node is busy writing massive blobs of transaction metadata to disk while simultaneously trying to calculate fraud rings in real time.
- With Infinigraph: Full ACID compliance ensures data integrity across the cluster. Transactions write smoothly because the heavy metadata payloads are hashed and spread across the property shards via transaction logs. Your fraud analysts run real-time queries against the lean graph topology shard without hitting a performance ceiling.
The Bottom Line
If you’ve been holding back on using graph technology for your heaviest enterprise datasets because you were worried about hitches at scale, the ceiling has officially been removed. With Infinigraph now available for property-heavy workloads, you can confidently design large-scale Knowledge Graphs, real-time fraud engines, or massive GraphRAG applications knowing the database will grow with your data.
The era of the infinite graph is here. Go build something massive.

Leave a comment